Combining crawl4AI, Supabase and N8N
![]()
Retrieval-Augmented Generation (RAG) - A brief overview
Retrieval-Augmented Generation (RAG) is a powerful technique that combines the generative strength of large language models (LLMs) with the precision of retrieval-based systems. Instead of relying solely on a model’s internal knowledge, RAG pipelines dynamically pull in relevant external data—like documents, websites, or databases—at query time. This dramatically improves the factual accuracy and adaptability of LLMs, especially in domain-specific or frequently updated contexts.
At its core, a RAG workflow retrieves contextually relevant chunks of information using semantic search (typically via vector embeddings), then passes this context along with the user’s question into an LLM. The result is a grounded, contextualised answer that’s both coherent and informed by up-to-date data. Whether you’re building an internal knowledge assistant or a public-facing chatbot, RAG helps ensure your AI is informed, not just intelligent.
The services and tech needed to crawl a website and chat with the content
We’ll briefly cover the various parts of our RAG prototype made of:
- A Supabase database to hold the data (hosted by Supabase so n8n can access it remotely)
- n8n to create a workflow with a chat and AI agent functionality
- A python repo to run Crawl4AI locally and embed the documents using a local Ollama container. See Crawl4AI domain crawler.md.
- An Ollama service deployed on Digital Ocean (so n8n can access it remotely). See Ollama on Digital Ocean.md.
n8n
n8n is an open-source, low-code workflow automation tool that allows you to connect APIs, services, and custom logic with ease. It provides a visual interface where users can build complex automation pipelines by simply dragging and dropping nodes.
With native support for hundreds of integrations and the ability to run JavaScript code or call webhooks, n8n is a powerful platform for orchestrating data flows—perfect for building Retrieval-Augmented Generation (RAG) applications that combine scraping, embedding, storage, and AI querying into a seamless process.
You can either use the hosted version or self-host wherever you like. Sign-up and start automating.
Supabase
Supabase is an open-source backend-as-a-service that offers a powerful alternative to Firebase, built on top of PostgreSQL. It provides a fully managed database, real-time subscriptions, authentication, storage, and RESTful or GraphQL APIs out of the box.
With a developer-friendly interface and tight integration with modern toolchains, Supabase is ideal for hosting and querying embedded data in RAG applications, enabling fast, scalable, and secure data access.
Pre-requisites
You’ll need to set up a few accounts
- n8n account
- Supabase: Sign up and start a new project
- OpenAi account and API key. This is optional, you can also use other chat models in the agent.
Since the embeddings that will be created by our crawler are made with an Ollama model and we will be running n8n remotely, we need an Ollama service deployed remotely. Follow our tutorial Ollama on Digital Ocean.md to set up Ollama remotely on Digital Ocean.
Implementation of a RAG in n8n
Now let’s dive straight into the implementation. We’ll setup two tables in Supabase and create an n8n workflow with an AI Agent that can use it as a tool.
Supabase init
We start with a SQL file that sets up the foundational schema for using Supabase as a vector database to support RAG. The file can be found here. We split it into three part here, to make it more readable.
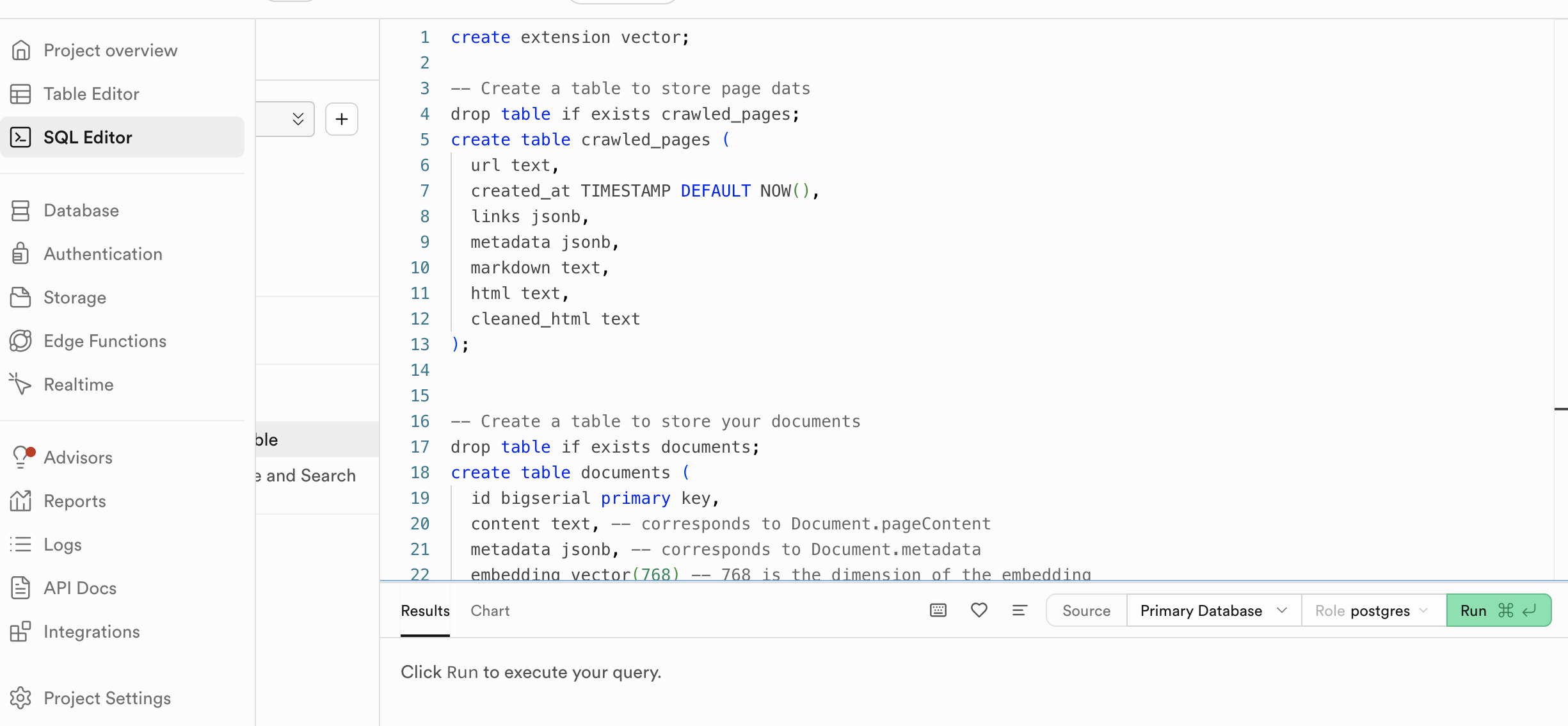
First, we enable the pgvector extension, which allows for storing and querying high-dimensional vectors—essential for working with embeddings from language models. We then create two tables. One, crawled_pages, which stores raw and processed data from web crawls (including HTML, markdown, and metadata):
-- Enable the pgvector extension to work with embedding vectors
create extension vector;
-- Create a table to store page dats
drop table if exists crawled_pages;
create table crawled_pages (
url text,
created_at TIMESTAMP DEFAULT NOW(),
links jsonb,
metadata jsonb,
markdown text,
html text,
cleaned_html text
);The second table we create is documents, which holds the actual vectorised content used for semantic search, along with metadata and embeddings of dimension 768. We set the dimension to 768 because we will be using the nomic-embed-text model for creating our embeddings.
-- Create a table to store your documents
drop table if exists documents;
create table documents (
id bigserial primary key,
content text, -- corresponds to Document.pageContent
metadata jsonb, -- corresponds to Document.metadata
embedding vector(768) -- 768 is the dimension of the embedding
);The final part of the script defines a custom SQL function: match_documents. It performs a vector similarity search using the <=> operator to compute cosine distance between the query embedding and stored document embeddings.
Further, it supports optional filtering based on JSON metadata and returns the most similar documents sorted by relevance. This function enables efficient retrieval of contextually relevant content for use in our RAG pipeline.
-- Create a function to search for documents
create function match_documents (
query_embedding vector(768),
match_count int default null,
filter jsonb DEFAULT '{}'
) returns table (
id uuid,
content text,
metadata jsonb,
similarity float
)
language plpgsql
as $$
#variable_conflict use_column
begin
return query
select
id,
content,
metadata,
1 - (documents.embedding <=> query_embedding) as similarity
from documents
where metadata @> filter
order by documents.embedding <=> query_embedding
limit match_count;
end;
$$;To run the script open the SQl Editor in your Supabase project, paste the
snippets and click RUN.
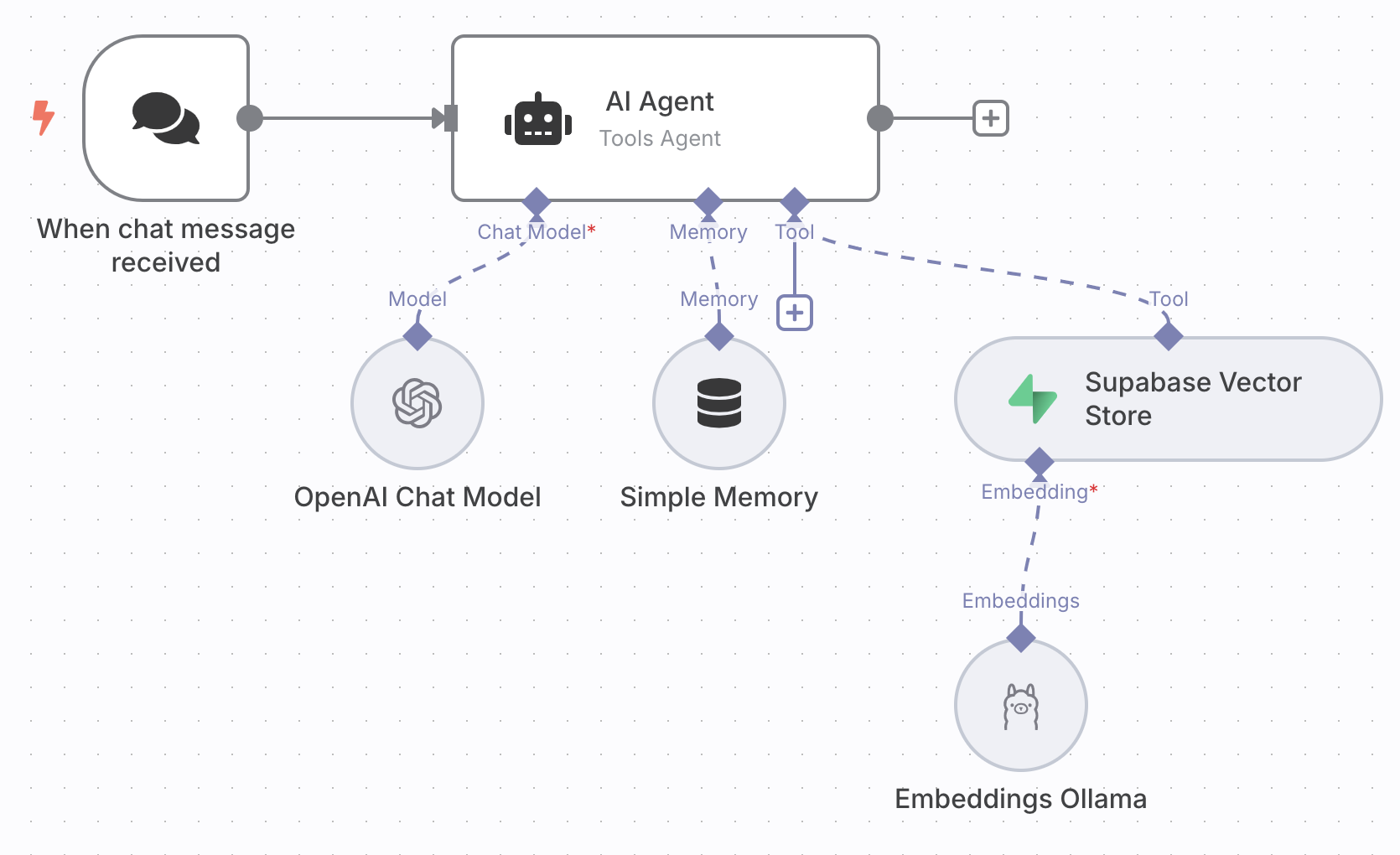
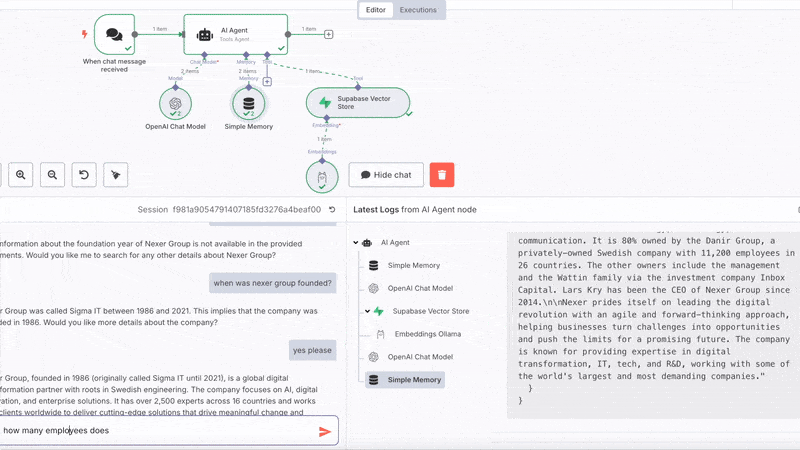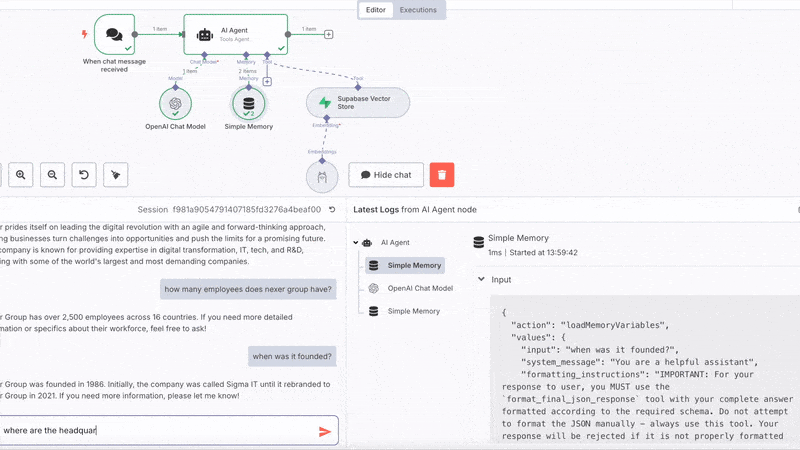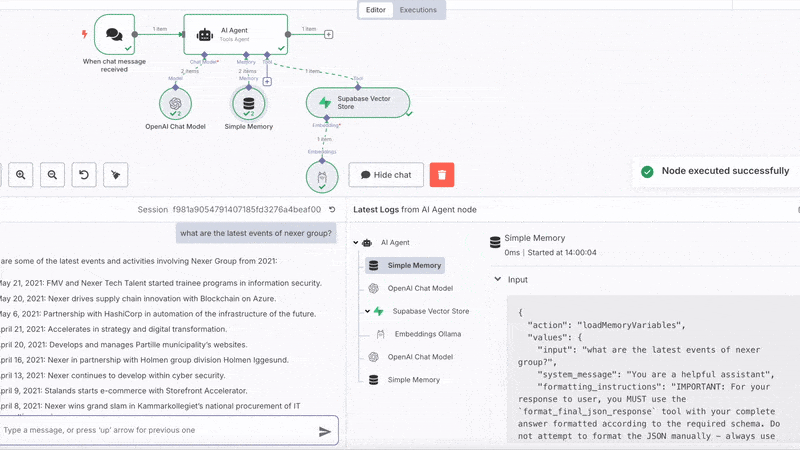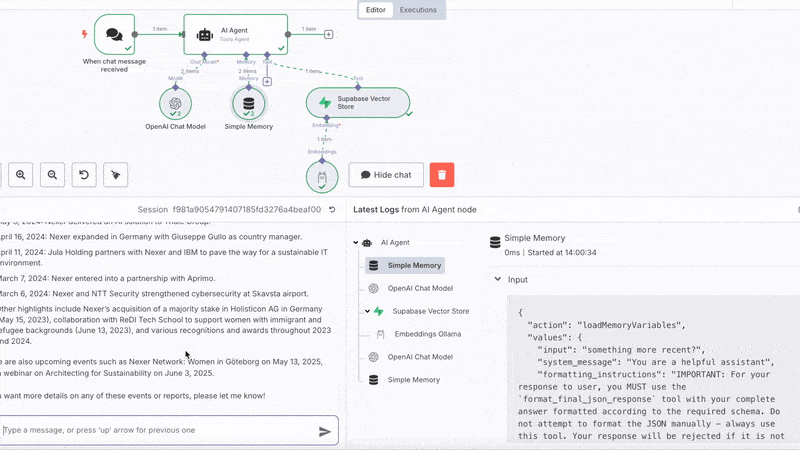
The n8n RAG workflow
The n8n workflow is straightforward
- A chat node
- An AI Agent connected to an OpenAi Chat Model (set up with your credentials, you can also pick another model and provider)
- Simple memory
- Supabase Vector Store tool using Ollama Embeddings
Selecting and connecting the nodes is the easy part and done in a second. We’ll now walk through configuring them.
Setting up the Supabase Vector Store Node
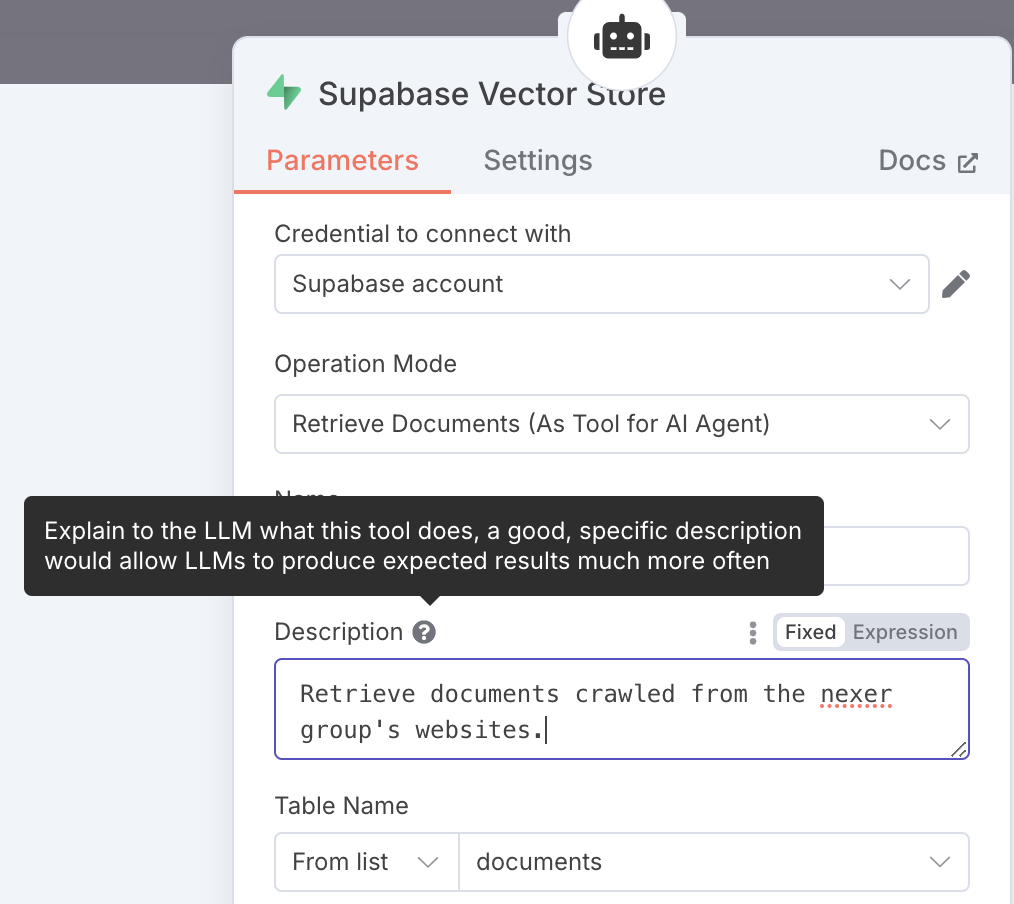
To set up the Supabase Vector Store node in n8n you need to:
- Provide
SUPABASE_URLasHostandSUPABASE_KEYasService Role Secretin theCredential to connect with...sub-menu - Write a good description for your agent to understand when and how to use the vectorstore tool
- Select the
documentstable that holds the embeddings
NOTE: The default SQL function that will be called to find documents is
match_documents, which is why we initialised and defined it in Supabase earlier.
Setting up Ollama embeddings
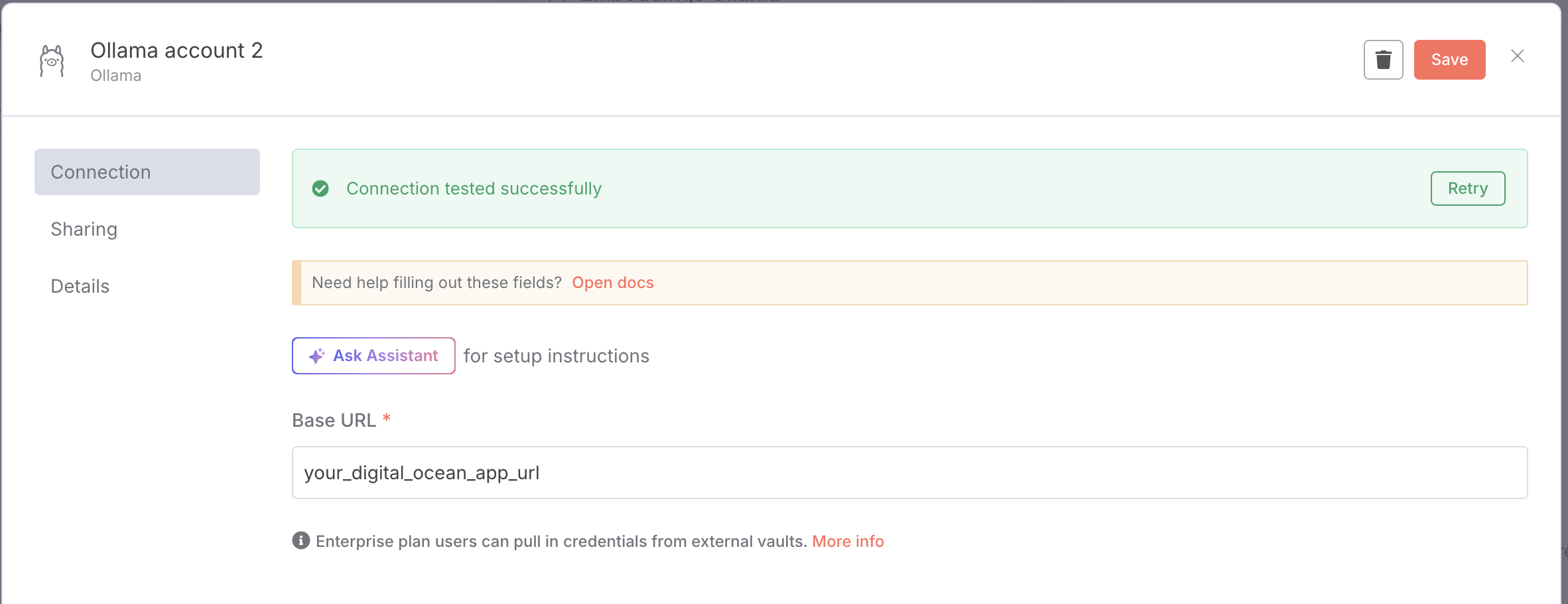
By default n8n’s Embeddings Ollama node is set to send requests to an Ollama service running on localhost. Since we are using a remote n8n instance, we don’t need have a localhost and we’ll configure the node to send requests to our Ollama app hosted on Digital Ocean.
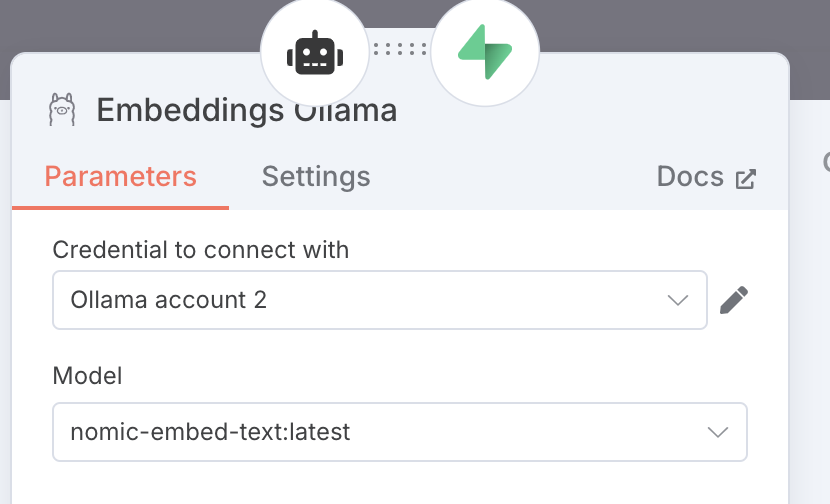
For configuring:
- Set the model to the same one used to create the embeddings (and the one pulled to the Ollama app).
- Click the edit button of
Credential to connect with - Set the Base URL with the URL from your remote ollama service
NOTE: Check out our quick tutorial to setup up an Ollama endpoint remotely on Digital Ocean Ollama on Digital Ocean.md.
Now we have set up everything we only need the data, so let’s dive straihgt into the crawler.
Run the crawl
Last step is setting up the crawler environment and we are ready to run the crawl and start chatting with your data. For that follow the guide Crawl4AI domain crawler and start crawling the domain you want to talk to.
First results
If you open your Supabase project you should start seeing the crawled_pages as well as the documents tables being populated.
Go back to your n8n workflow, open the chat of the chat node and should be able
to ask questions and get answers!
Next steps
Why not make your agent smarter and add the wikipedia tool node in n8n?!
Conclusion: A Simple, Flexible RAG Stack
With Crawl4AI, Supabase, and n8n, you now have a clear, modular setup for building Retrieval-Augmented Generation workflows. From crawling and embedding data to querying it through an AI agent, each component is open-source, easy to customise, and fits neatly into a broader automation pipeline.
This stack is a solid foundation for projects that need up-to-date, searchable knowledge—whether for internal tools, chatbots, or content analysis. Now that everything’s connected, all that’s left is to keep experimenting and expanding.