Host your own LLM with Ollama on DigitalOcean—cut costs, keep your data private, and gain full control over your AI stack.
![]()
Why Run Your Own LLM Instead of Using OpenAI or Google?
Hosted LLM APIs like OpenAI, Google, and Anthropic are great for getting started—but they come with tradeoffs: high per-token costs, limited control, and zero data privacy guarantees.
By running an open-source model like LLaMA using Ollama on your own infrastructure (e.g., via DigitalOcean), you get:
- Full control over the model, versioning, and updates
- Flat, predictable costs—no surprise bills
- Data privacy by design—your data never leaves your cloud
- Customizability—swap models, fine-tune, or run offline
With tools like Ollama and DigitalOcean, deploying your own LLM server is fast, affordable, and production-ready. In this guide, we’ll show you how to set it up in minutes—no API keys, no lock-in.
LLaMA and ollama
LLaMA (Large Language Model Meta AI) is a family of open-source large language models developed by Meta, designed to provide high performance while being more resource-efficient than many other models in the same class. LLaMA models have been widely adopted in the AI community for their accessibility, strong multilingual capabilities, and ease of fine-tuning on domain-specific tasks. They are particularly well-suited for building local, privacy-respecting applications such as RAG (retrieval-augmented generation) systems, chatbots, and summarizers—especially when low-latency inference is required without relying on external APIs.
Ollama is a developer-friendly tool that simplifies the deployment and management of LLaMA and other open-source language models via Docker containers (see git-repo and docker-hub). It abstracts away the complexity of setting up inference servers by offering a clean interface to run models locally with just a few commands. With Ollama, you can easily load, switch, and interact with LLaMA models using HTTP endpoints—making it an excellent choice for embedding models into workflows like n8n or integrating with data pipelines hosted on platforms like Supabase. This streamlined setup allows developers to run powerful LLMs on their own infrastructure, reducing dependencies on cloud-based services and improving control over cost and data privacy.
Digital Ocean
DigitalOcean is a cloud infrastructure provider known for its simplicity and developer-friendly tools. It offers scalable virtual machines (droplets), managed databases, and Kubernetes clusters, making it a popular choice for hosting applications, including LLM inference servers like Ollama, for around 20$ per month. We’ll be making use of the option to deploy a docker file from your GitHub repository.
Implementation
Let’s walk through the steps to deploy an app on Digital Ocean from a dockerfile on GitHub.
Pre-requisites
- Digital Ocean account
- Github account
A simple Ollama Dockerfile
Create a repo on GitHub with the following Dockerfile:
# Start from the official Ollama image as the builder stage
FROM ollama/ollama:latest AS builder
# Define a build-time argument for the model name, allowing it to be passed when building the image
ARG MODEL_NAME_ENV
# Set an environment variable with a default model if none is provided
ENV MODEL_NAME=${MODEL_NAME_ENV:-nomic-embed-text}
# Start the Ollama server in the background, wait a bit for it to initialize,
# then pull the specified model so it's available in the final image
RUN ollama serve & \
sleep 3 && \
ollama pull ${MODEL_NAME}
# Use a fresh Ollama image for the final stage to keep it clean and minimal
FROM ollama/ollama:latest
# Copy the downloaded model data from the builder stage to this image
COPY --from=builder /root/.ollama /root/.ollama
# Set the default command to start the Ollama server when the container runs
CMD ["serve"]This Dockerfile sets up a minimal Ollama-based container for serving an LLM
model, using a two-stage build to preload the specified model (defaulting to
nomic-embed-text in our case)
and copy it into a clean runtime image.
NOTE: While it’s well-suited for development or prototyping, it should not be used in production environments as it lacks essential security configurations such as authentication, encrypted communication (TLS), and resource restrictions.
Ollama doesn’t support setting an API Key. The Ollama team recommends using a reverse proxy. Here’s a good article on a workaround.
We’ll keep it simple and deploy our dockerfile on Digital Ocean.
Deploy the Dockerfile on Digital Ocean
In Digital Ocean log into your account and:
- create a project
- click
create>App Platform - connect to your
GitHubaccount - select the repo with the Dockerfile you want to deploy
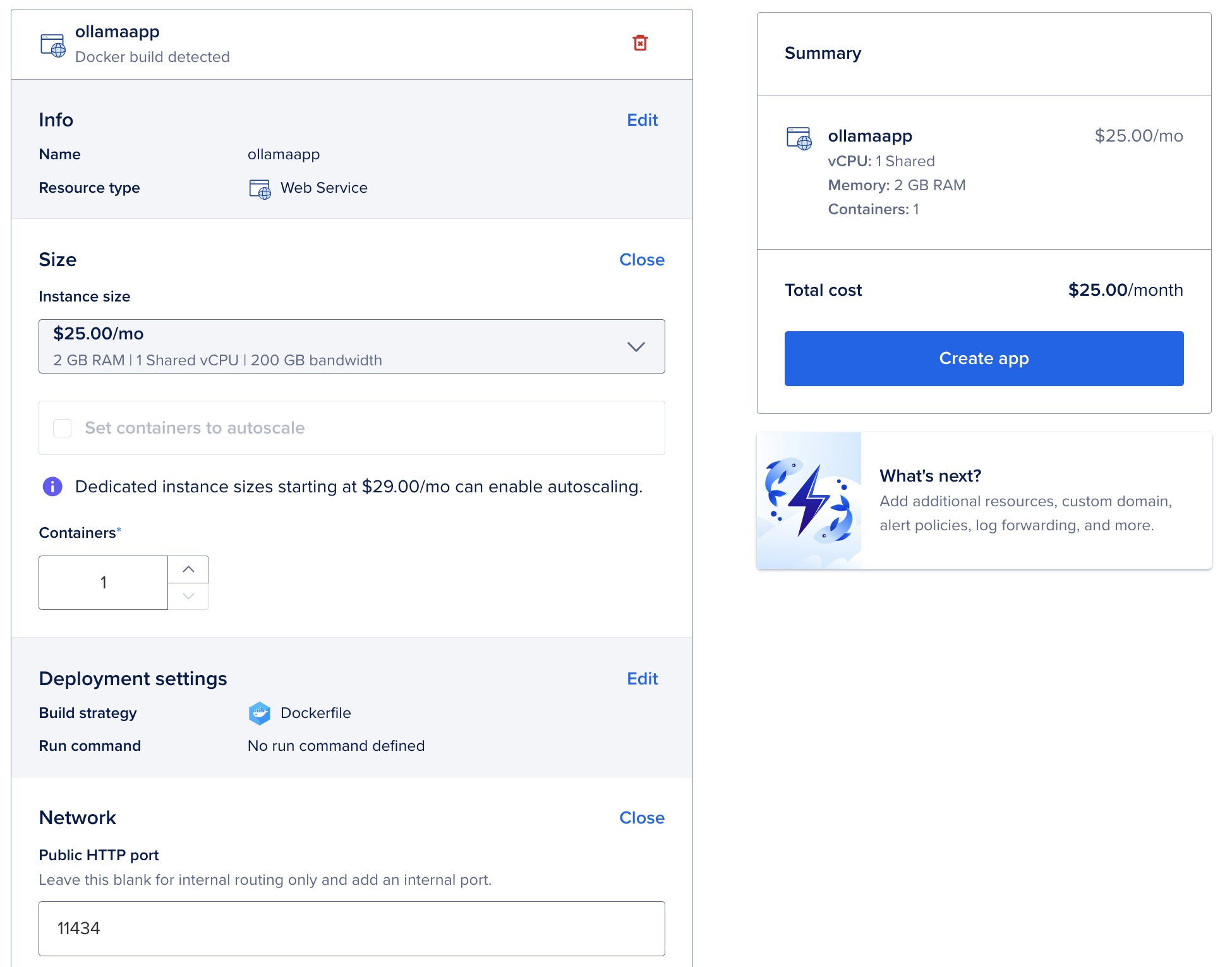
The default setting is 2 containers on 1GB RAM (2 x 12$ per month at the time of writing). We picked 1 container on a 2GB RAM instance (it costs almost the same: 25$ per month) to give it a bit more RAM.
The default public port is 8080, ollama is serving on port 11434, so we set that as the Public HTTP port of our app.
After clicking Create app you’ll have access to the URL,
copy it for sending requests to ollama or setting up your n8n workflow.
The best part: Every time you push changes to your repo Digital Ocean will re-build and re-deploy.
Conclusion
Hosting your own language model using Ollama on a cloud provider like DigitalOcean gives you full control over how your AI runs—without depending on third-party APIs or sending sensitive data to external services. Whether you’re building a RAG system, embedding workflows in n8n, or powering a domain-specific chatbot, this setup provides privacy, speed, and cost predictability.
While services like OpenAI, Google, or Anthropic offer convenience, they also come with constraints—rate limits, vendor lock-in, and recurring API costs. By self-hosting with Ollama, you gain the flexibility to scale, experiment, and integrate open-source LLMs into your own infrastructure on your terms.